
The Query Tree input file reads the nodes one by one and immediately
reads their childs. So the tree is read in using preorder traversal. Recall
the table of classIndex aliases:
| Name | Alias |
| sxpPCatObject | pobj |
| sxpPCatField | pfld |
| sxpPCatRun | prun |
| sxpPCatDescriptor | pdes |
| sxpSCatObject | sobj |
| sxpSCatTarget | stgt |
The format of the nodes is the following:
Union: indicated by an U, followed by the number of children, the class alias and whether it is distinct (0 or 1 for false, true respectively).
U <nChildren> <classIndex Alias> <distinct>
Intersection: Same as Union (indicated by an I) but it does not need number of children (always 2).
I <classIndex Alias> <distinct>
Except/Difference: Indicated by an E, same as Intersection
E <classIndex Alias> <distinct>
Bag Query: Indicated by a B, it also needs the class index alias and distinct flag. Additionally, there is a predicate string enclosed in double quotes.
B <classIndex Alias> <distinct>
"Predicate string"
Association Query: Indicated by an A, the same as B and it takes the additional string of association name which is a list of classindex aliases separated by dots.
A <classIndex Alias> <distinct> <assoc Name>
"Predicate string"
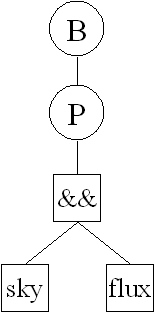
Predicate Tree: Indicated by a P, it also has a class Index alias. Since this always will give a distinct set, there is no need for a distinct flag. Another flag indicates whether an Intersection object is also printed in the file. (1: yes 0:no).
P <classIndex Alias> <hasIntersection>
<Predicate Tree>
<<Intersection Object>>
it is followed by the predicate tree (whose format is discussed below)
and the intersection object, eventually (if hasIntersection == 1).
The format for the Predicate Tree file is similar to the Query Tree. Again, preorder traversal is used. The OpNodes are never followed by anything except && and || which are followed by their number of children. The OpNodes are represented by their symbols
Operational Nodes
| Symbol | Name |
| && | Logical conjunction operator |
| || | Logical disjunction operator |
| ! | Logical negation operator, unary |
| > | Greater than |
| < | Less than |
| >= | Greater equal |
| <= | Less equal |
| =, == | Equality relation |
| <>, != | Inequality |
| =~ | Regular expression string comparison |
| !~ | NOT form of regular expression string comparison |
| =~~ | Case insensitive regular expression string comparison |
| !~~ | Case insensitive NOT form of regular expresstion string comp |
| + | Addition |
| - | Subtraction or unary minus |
| * | Multiplication |
| / | Division |
| % | Remainder |
The leaf nodes may be
| Symbol | Followed by |
| int | an integer |
| real | a float |
| str | a string in double quotes |
| regexp | a string in single quotes |
| sky | a sky domain |
| flux | a flux domain (see below for i/o format) |
The Sky Domain has the following i/o format:
<nConvexes>
<Convex1>
<Convex2>
.
.
<ConvexN>
where nConvexes is an integer giving the number of convexes. The Sky Convex has a similar i/o format:
<nConstraint>
<Constraint1>
<Constraint2>
.
.
<ConstraintN>
where nConstraint is an integer giving the number of Constraints in
a Convex.
The Constraint has the format
<x> <y> <z> <d>
Sky Constraints define a cone on the sky. (x,y,z) defines the normal vector (direction where the cone is pointing to) and d defines the distance where the normal vector hits the base plane of the cone, so the opening angle is arccos(d).All of these numbers are floats.
Constraints are logically ANDed in a Convex, i.e. only those regions in the sky are in the convex which lie within each of the cones defined in a Convex. A Domain is then the logical OR of Convexes. In this manner we can have a complete patchwork of the sky within one single Sky Domain.
The Flux Domain has the same i/o format as the Sky Domain:
<nConvexes>
<Convex1>
<Convex2>
.
.
<ConvexN>
The Flux Convex has an additional parrameter:
<nConstraint> <OutlierFlag>
<Constraint1>
<Constraint2>
.
.
<ConstraintN>
The OutlierFlag specifies whether regular (1) or outlier (2) or both
(3) objects should be considered. If this flag is 0 then none will be considered,
it is as we had no Convex at all. The FluxConstraint has the following
format:
<u> <g> <r> <i> <z> <c>
These are the coefficients defined in section Class Design Structure.
This is an example of a Query Tree input file for a simple Bag Query